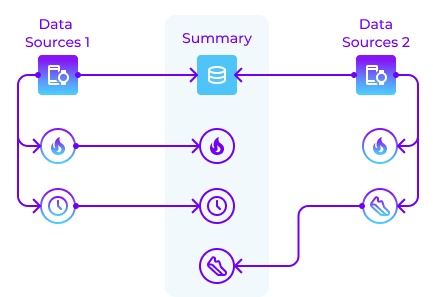
Data Collection
At ROOK, we offer comprehensive solutions for integrating health data from wearables through both API-based and SDK-based approaches. Each method is designed to accommodate different technological needs and project scopes, ensuring that developers can find the most effective and efficient way to integrate health data into their applications.
Both integration methods leverage ROOK's robust capabilities to provide meaningful health data, enhancing the user experience and empowering developers to create innovative health and fitness applications.
Connections Page
To enable your users to connect their data sources, a Connections Page is essential for your production stage. For developers using our sandbox environment, refer to our pre-configured Connections Page for easier integration and faster testing.
To develop a custom Connections Page (web or application-based), use the following endpoint:
/api/v1/client_uuid/<uuid:client_uuid>/user_id/<user_id>/data_sources/authorizers
This endpoint provides a list of data sources, icons, and authentication URLs for integration on your Connections Page.
Creating Your Own Connections Page
To set up a custom "Connections Page", follow these steps:
- Initiate a GET request to the provided endpoint.
- The endpoint will return a JSON response with a list of data sources, icons, and authentication URLs.
- For each data source, create a button on your Connections Page.
- Each button should redirect the user to the respective authentication URL (auth_url), where they can authorize ROOK to access their health data.
A user's authorization to share their health data with ROOK, or your company, is required only once. This ensures continued access to their health data without needing new authorizations, unless there are changes by the data source or new user permissions are needed.
Users can unlink a Health Data Source from their account, which will result in a loss of access to their information.
Connections Page In Sandbox
We offer a pre-configured "Connections Page" within the Sandbox Environment, streamlining the process of rapid application development or proof of concept. With this feature, you can concentrate on your development tasks while we take care of the initial setup.
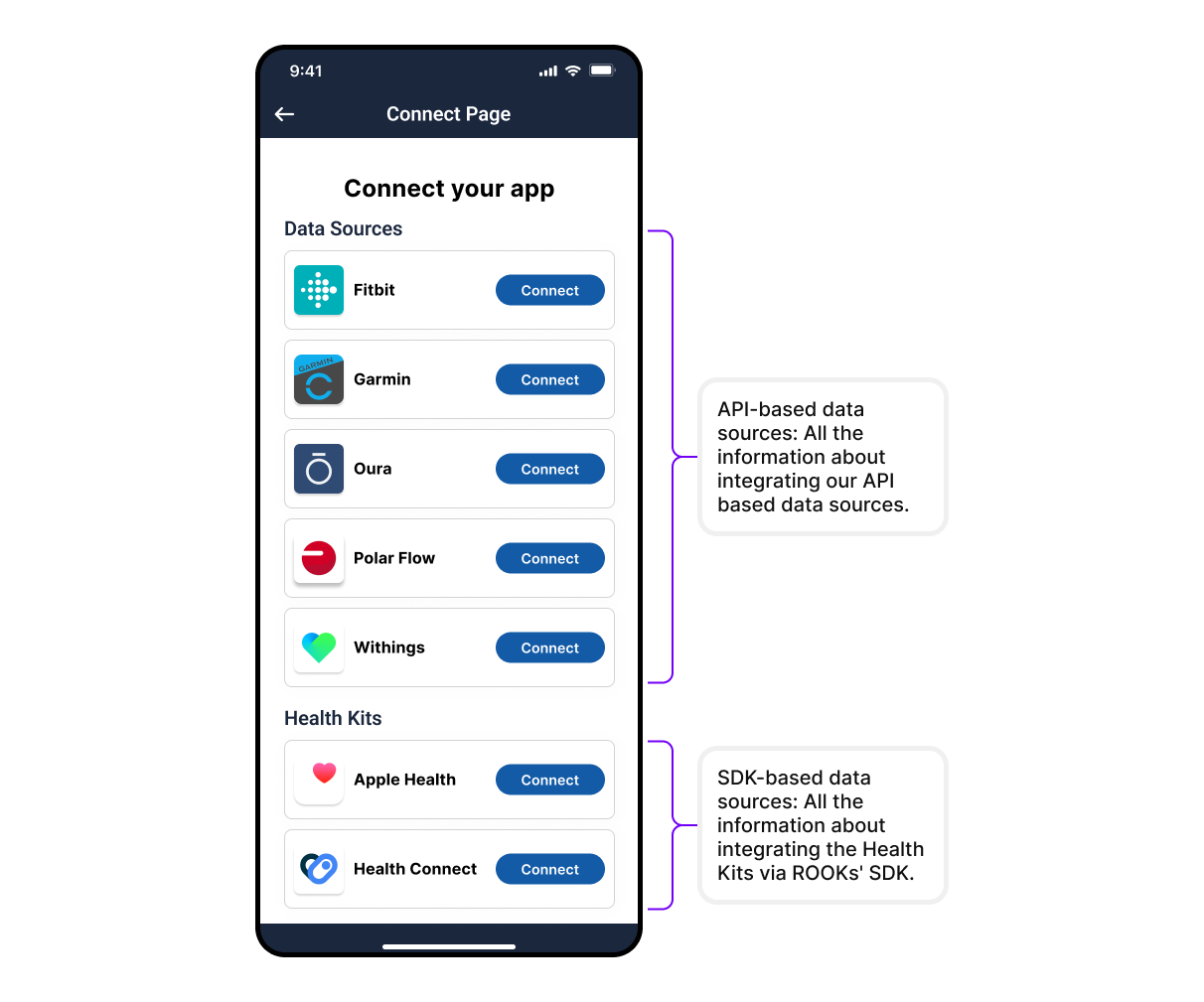
Ensure to use a unique user identifier (user_id) for linking user information:
- Users may have multiple email addresses across different Health Data Sources.
- We do not store email addresses used during the authorization process.
- The provided user_id will serve as the unique identifier.
Usage Example
Embed the Connections Page within a web view in your app using the following structure:
https://connections.+domain/client_uuid/your_client_uuid/user_id/your_user_id
Remember, this URL is intended solely for the Connection Page in Sandbox. For accessing other ROOK resources, such as API queries or webhooks, please refer to the corresponding repository.
For instance, a client identified by client_uuid: "d2c34b45-51ff-4ef0-95dc-d87c39136469" and using a development stage might use the user_id: aUniqueUserIdABCD1234.
https://connections.rook-connect.com/client_uuid/d2c34b45-51ff-4ef0-95dc-d87c39136469/user_id/aUniqueUserIdABCD1234/
The provided example of a Connections Page URL uses a demo client_uuid. Avoid including sensitive or personal information in public documentation.
SDK
Our SDKs are specifically designed to enhance the utility of your projects across various technologies. We provide robust SDKs for both Health Connect and Apple Health.
At ROOK, our focus is on optimizing SDK deployment. We ensure that our Monolithic SDKs are compatible with Android, iOS, React Native, and Flutter platforms, facilitating seamless integration.
For more information about our SDKs and supported technologies, please visit here.
Benefits of Monolithic SDKs
- Architecture: A monolithic SDK consolidates all essential functions for data collection and transmission into a single library. This integration simplicity often makes it a preferable choice for projects requiring rapid deployment.
- Ease of Integration: Typically involves adding one library to your project, simplifying the development process by handling all functionalities in one step.
- Scope: Although convenient, monolithic SDKs may have a larger footprint, which can impact performance, especially in complex applications.
Monolithic SDKs facilitate rapid deployment, whereas modular SDKs offer enhanced flexibility and optimization opportunities. When selecting an SDK, consider your project's complexity, performance requirements, and maintenance needs. For a tailored integration experience, explore our modular SDK framework, which allows for selective feature integration customized to your application’s specific needs. For further details, Contact us.
Time Zone
The Time Zone feature customizes scheduled queries for each end-user based on their geographic time zone. This customization ensures that users receive their health data summaries at the most relevant local time, enhancing the timeliness and relevance of the information. For example, sleep summaries are delivered simultaneously across different time zones, ensuring consistency whether the user is in the USA or the UK.
Data Cleaning
The Data Duplicity feature merges information from various data sources, providing our clients with high-quality, consolidated data. This process ensures data integrity and reliability, enabling effective decision-making based on comprehensive health data insights.
Data Prioritization
We prioritize data sources based on the quality and comprehensiveness of the information they provide. This ranking informs our processing and is critical for ensuring the best possible data quality.
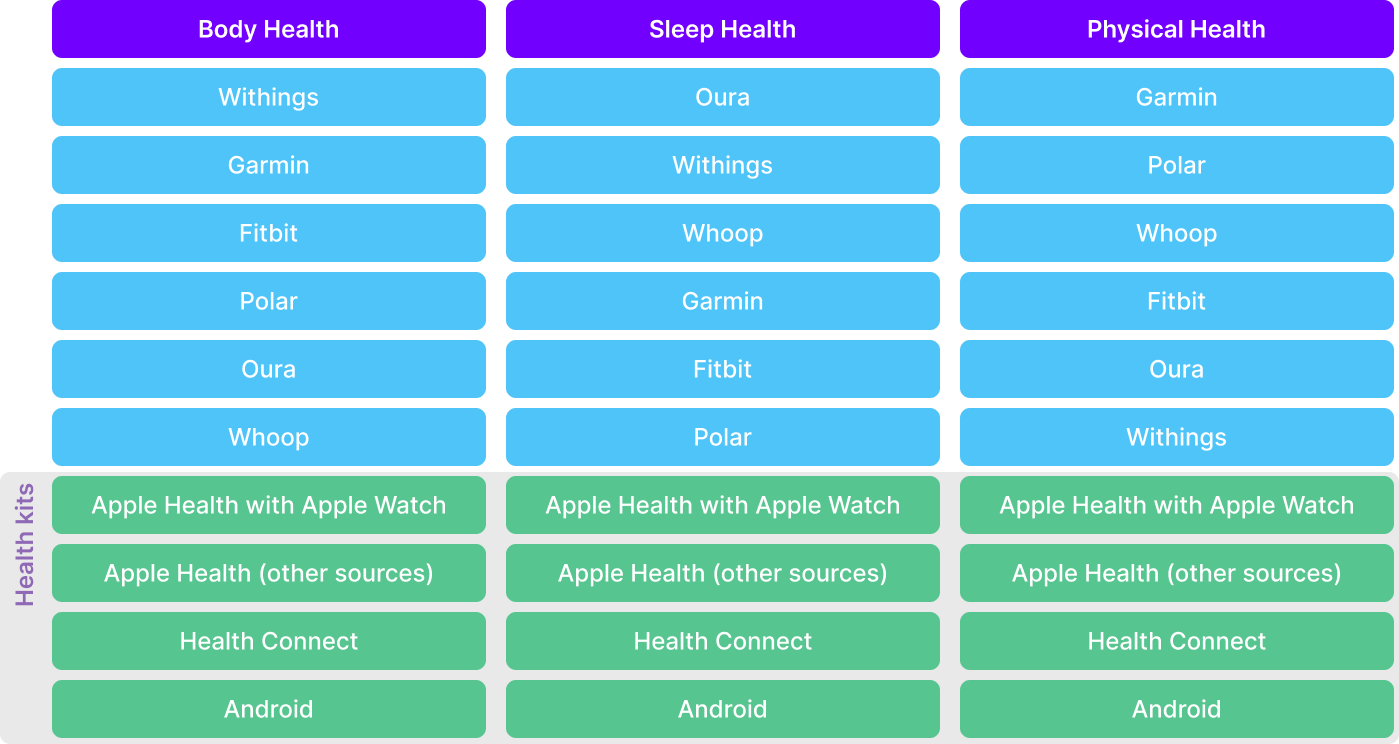
There are also complementary rules for prioritizing and creating more robust data structures. These are two:
Non-Null Value
The new value, regardless of priority, has a non-null value
- If the data source with the highest priority returns a variable with a Null value and another data source returns the same variable with a value of 10, the latter value from the data source with the lowest priority will be used.
- If the data source with the highest priority returns a variable with a value of 0 and another data source returns the same variable with a value of 10, the latter value from the data source with the lowest priority will be used.
Higher Value
The new value has a higher value, regardless of priority. This rule is only available or applied to a few variables.
{
'calories_intake_number',
'steps_number',
'accumulated_steps_int',
'calories_net_intake_kilocalories',
'calories_expenditure_kilocalories',
'calories_net_active_kilocalories',
'calories_basal_metabolic_rate_kilocalories',
'activity_duration_seconds',
'active_seconds',
'rest_seconds',
'low_intensity_seconds',
'moderate_intensity_seconds',
'vigorous_intensity_seconds',
'inactivity_seconds',
'steps_per_day_number',
'active_steps_per_day_number',
'calories_intake_number',
}
Identifying Complementary Events
Our system processes and prioritizes events to avoid duplications, focusing on data directly from wearable devices over SDK extractions and health kits.
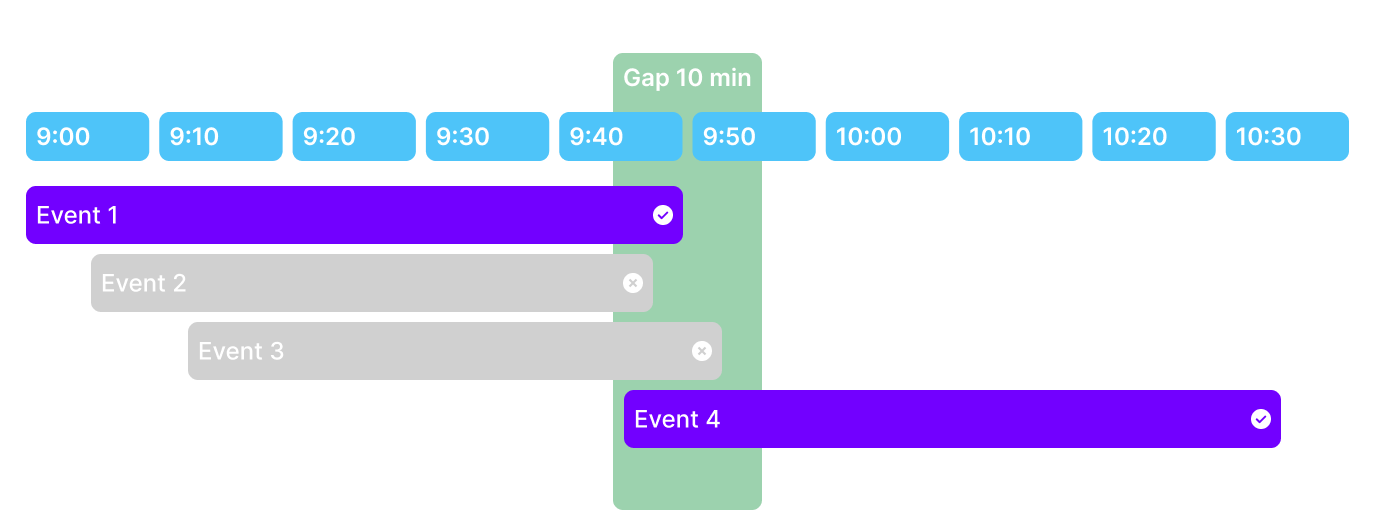
Generating Complementary Summaries
Summaries are initially generated from the primary data source and are subsequently enhanced with additional data. We maintain a strict 15-minute update interval to ensure data accuracy. These enhanced summaries are labeled as updated versions along with their corresponding version numbers.
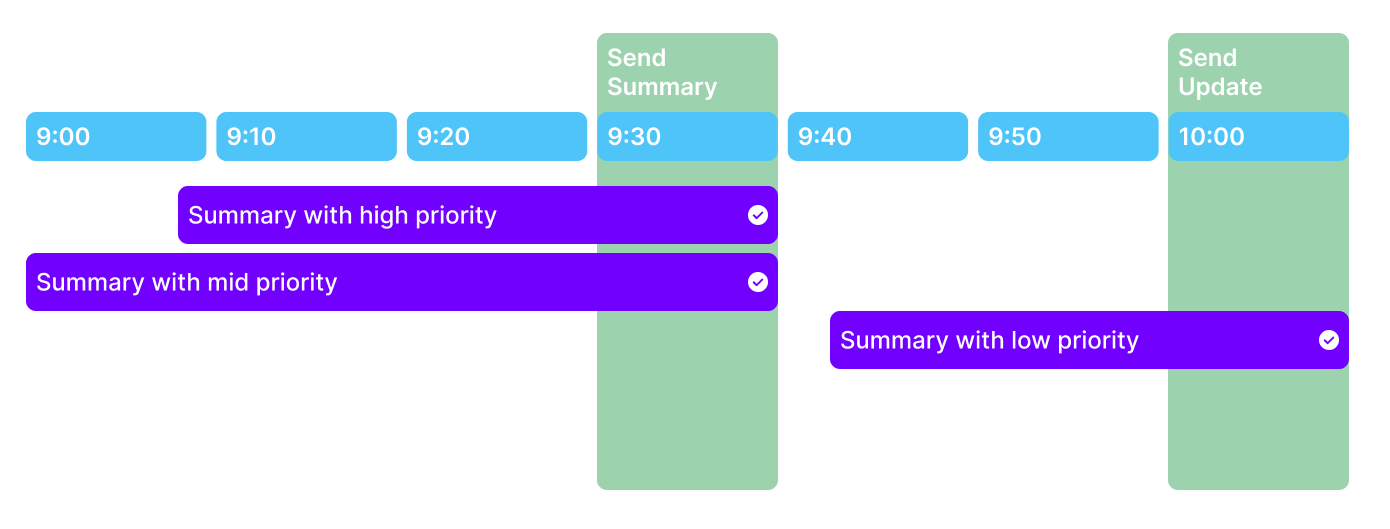
Combining Data Into Summaries
When integrating data from multiple summaries related to the same period, our system adheres to a strict methodology that respects the prioritization of data sources, ensuring that the most relevant and accurate information is always presented.