Data Processing
Once extracted, health data undergoes a robust processing pipeline consisting of five core stages: harmonization, standardization, cleaning, normalization, and structuring. This workflow ensures that information from multiple heterogeneous sources is consolidated into high-quality, actionable schemas. During the cleaning phase, applies strict source prioritization rules and utilizes the document_version field in conjunction with the datetime to resolve duplicates and safely manage payload updates.
Once data is captured through Data Extraction, it undergoes a robust processing phase before delivery via webhooks or the ROOK API. This step ensures that data is harmonized, standardized, cleaned, normalized, and structured to provide optimal quality, consistency, and usability.
Key Processing Steps
ROOK’s data processing pipeline consists of five core stages:
These stages enable ROOK to deliver high-quality, consolidated, and structured health data.
1. Data Harmonization
Harmonization ensures consistency across data formats, units, and definitions from diverse sources.
Examples:
- Converting distance values into a unified unit (for example, kilometers).
- Adjusting timestamps to align with the user’s local time zone.
Outcome: Uniform and consistent data representation across all health data sources.
2. Data Standardization
Standardization applies recognized industry standards to collected data, ensuring compatibility and reliability across different health data providers.
Examples:
- Mapping sleep stages from various providers to a common standard.
- Aligning heart rate intervals for consistent reporting.
Outcome: Standardized data compatible with cross-platform integration.
3. Data Cleaning
Data cleaning eliminates inconsistencies, resolves duplicates, and ensures the reliability of delivered data. This step integrates ROOK’s Duplicity Feature for managing data from multiple sources.
Key Components of Cleaning
-
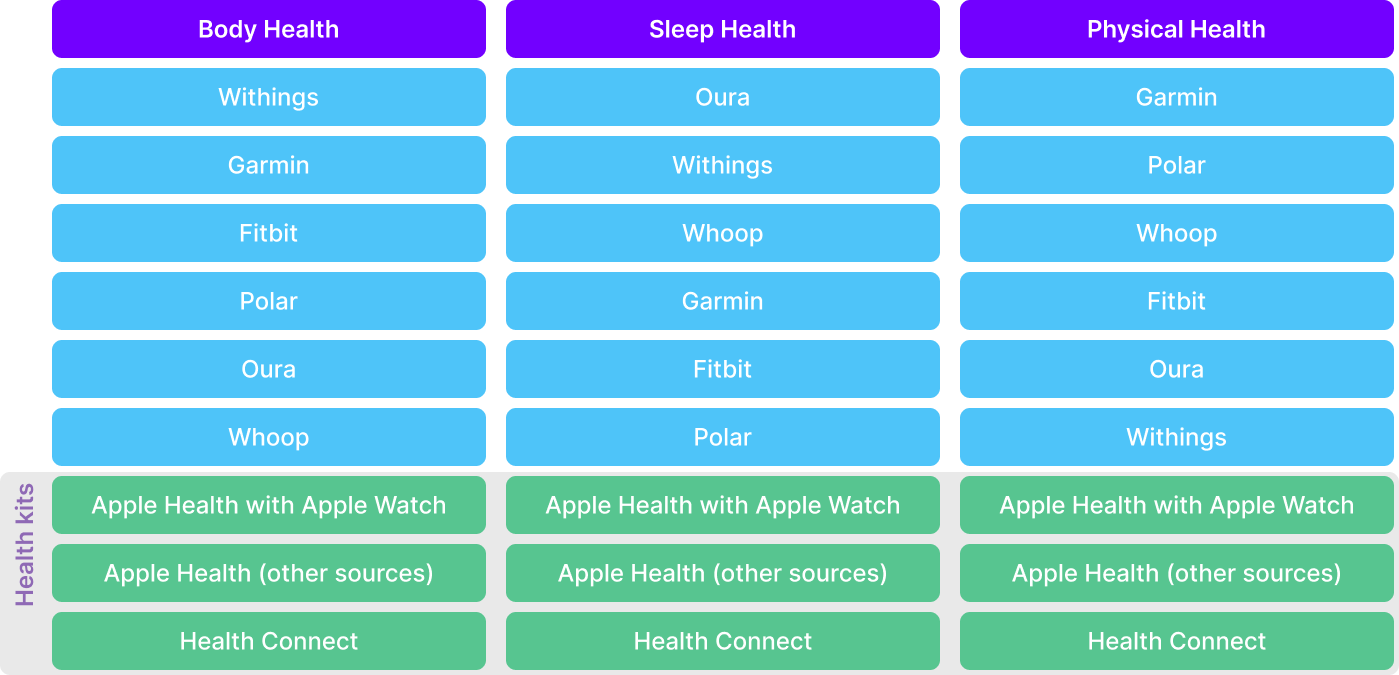
Data Prioritization:
- Data sources are ranked based on their quality, comprehensiveness, and relevance.
- Wearable device data takes precedence over SDK extractions and health kits.
-
Rules for Data Prioritization:
- Non-Null Value Rule: Valid non-null values from lower-priority sources override null values from higher-priority sources.
- Higher Value Rule: For specific metrics (for example,
steps_number,calories_expenditure_kilocalories), the highest value is retained, regardless of source priority.
-
Event Processing:
- Events from multiple sources within a ±10-minute window are merged or prioritized based on source ranking.
- Redundant events are discarded, ensuring a clean event record.
-
Summary Processing:
- Summaries are generated using the highest-priority data source.
- Updates to summaries incorporate complementary data from secondary sources, ensuring enriched details.
- Updated summaries are versioned for traceability using the
document_versionkey.
document_version identifies the most recent version of a dataset sent by ROOK, but it is only valid when it corresponds to the same datetime.
The logic is simple:
- If a higher version arrives and the datetime matches, replace the entire dataset.
- If the datetime does not match (for example, it belongs to a previous day), the dataset must not replace the current one, even if the version is higher.
- If a lower version arrives, it should be discarded.
For more information, refer to the document_version usage guide.
Update Frequency for Summaries
- Summaries are retained for 15 minutes before delivery to incorporate delayed updates from connected sources.
- All data is ultimately reported in UTC for consistency.
Outcome: Clean, accurate, and enriched data that eliminates redundancies while preserving the best information.
4. Data Normalization
Normalization adjusts data to a uniform scale and format, ensuring comparability across sources.
Examples:
- Converting calorie data to a standardized unit (for example, kilocalories).
- Aligning step counts into consistent time intervals.
Outcome: Normalized data that is actionable and comparable across diverse data sources.
5. Data Structuring
ROOK organizes all processed data into structured schemas, which unify metrics across various sources. These schemas ensure that clients receive consistent data, regardless of the original source.
- Schemas: Detailed structures for Physical, Sleep, and Body Health pillars.
- Key Benefits:
- Consistent formatting and simplified integration for developers.
- Predefined keys mapped across data sources for uniform data handling.
Explore schemas in the Data Types section for further details.
Why Data Processing Matters
- Enhanced Data Quality: Ensures high-quality, actionable data for client applications.
- Cross-Source Integration: Harmonizes data from multiple sources into a single, consistent format.
- Streamlined Analysis: Structured and cleaned data simplifies downstream usage.
- Standardized Reporting: All data is delivered in UTC for global consistency.